Die Tatsache, dass wir nun Daten in einen Kontext gebracht haben, ist aber ebenso wie die Beschaffung von den richtigen, vertrauenswürdigen Rohdaten noch nicht ausreichend und ermöglicht es auch noch nicht, schnelle und “smarte” Erkenntnisse zu gewinnen.
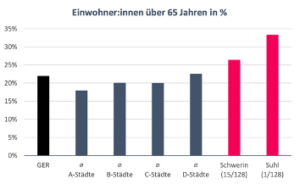
Um wirklich innerhalb von Sekundenbruchteilen relevantes Wissen aufzubauen, ist es unabdingbar, die neu gewonnenen Informationen entsprechend zu visualisieren. Betrachten wir nun Abbildung 1, so können wir sofort auf einen Blick ableiten, dass in Schwerin, als D-Stadt, tatsächlich ein überdurchschnittlich hoher Anteil an Senioren lebt. Mit 26,4% liegt Schwerin hierbei auf Platz 15 unter den 128 ABCD Städten in Deutschland. Spitzenreiter, ebenfalls in die Grafik eingeblendet, ist die thüringische Stadt Suhl.
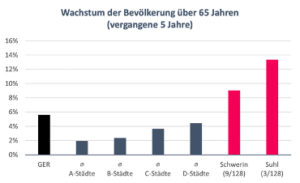
Wenn wir dieselbe Visualisierung für die historische Entwicklung des Anteils an Senioren anwenden, erkennen wir sogar, dass sich der Anteil der Senioren in Schwerin in den vergangenen 5 Jahren deutlich überdurchschnittlich entwickelt hat. Mit 10,4% Wachstum liegt Schwerin hier auf Platz 6 von 128 ABCD Städten und auch deutlich über dem deutschen Schnitt.
Die korrekte, präzise aber auch einfache Visualisierung ermöglicht es also, quasi jedem Leser, auf Basis von nun “smarten” Daten sehr schnell neues Wissen zu gewinnen und so in kürzester Zeit verbesserte Entscheidungen, beispielsweise für oder gegen ein Investmentobjekt, zu treffen.
